本文以最新的elasticsearch-6.3.0.tar.gz为例,为了节约资源,本文将副本调为0, 无client角色
https://www.elastic.co/blog/hot-warm-architecture-in-elasticsearch-5-x
以前es2.x版本配置elasticsearch.yml 里的node.tag: hot这个配置不生效了被改成了这个node.attr.box_type: hot
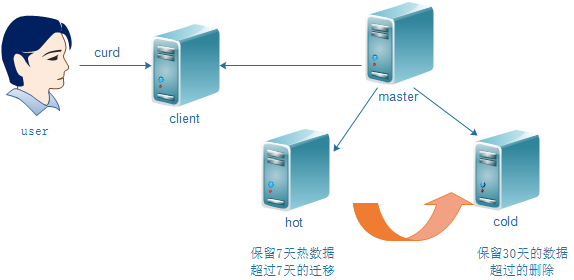
es架构
各节点的es配置
master节点:[root@n1 ~]# cat /usr/local/elasticsearch/config/elasticsearch.yml cluster.name: elknode.master: truenode.data: falsenode.name: 192.168.2.11#node.attr.box_type: hot#node.tag: hotpath.data: /data/es path.logs: /data/lognetwork.host: 192.168.2.11http.port: 9200transport.tcp.port: 9300transport.tcp.compress: truediscovery.zen.ping.unicast.hosts: ["192.168.2.11"]cluster.routing.allocation.disk.watermark.low: 85%cluster.routing.allocation.disk.watermark.high: 90%indices.fielddata.cache.size: 10%indices.breaker.fielddata.limit: 30%http.cors.enabled: truehttp.cors.allow-origin: "*"
- client节点(这里就不配置了)node.master: falsenode.data: false
- hot节点[root@n2 ~]# cat /usr/local/elasticsearch/config/elasticsearch.yml cluster.name: elknode.master: falsenode.data: truenode.name: 192.168.2.12node.attr.box_type: hotpath.data: /data/esnetwork.host: 192.168.2.12http.port: 9200transport.tcp.port: 9300transport.tcp.compress: truediscovery.zen.ping.unicast.hosts: ["192.168.2.11"]cluster.routing.allocation.disk.watermark.low: 85%cluster.routing.allocation.disk.watermark.high: 90%indices.fielddata.cache.size: 10%indices.breaker.fielddata.limit: 30%http.cors.enabled: truehttp.cors.allow-origin: "*"
- cold节点[root@n3 ~]# cat /usr/local/elasticsearch/config/elasticsearch.yml cluster.name: elknode.master: falsenode.data: truenode.name: 192.168.2.13node.attr.box_type: coldpath.data: /data/esnetwork.host: 192.168.2.13http.port: 9200transport.tcp.port: 9300transport.tcp.compress: truediscovery.zen.ping.unicast.hosts: ["192.168.2.11"]cluster.routing.allocation.disk.watermark.low: 85%cluster.routing.allocation.disk.watermark.high: 90%indices.fielddata.cache.size: 10%indices.breaker.fielddata.limit: 30%http.cors.enabled: truehttp.cors.allow-origin: "*"
如何实现某索引数据写到指定的node?(根据节点tag即可)
我hot节点打了tag
node.attr.box_type: cold
创建一个template(这里我用kibana来操作es的api)PUT _template/test{ "index_patterns": "test-*", "settings": { "index.number_of_replicas": "0", "index.routing.allocation.require.box_type": "hot" }} 
意思是test-*索引命名的,都将其数据放到hot节点上.
如何实现数据从hot节点迁移到老的cold节点?
以test-2018.07.05索引为例,将它从hot节点迁移到cold节点
kibana里操作:PUT /test-2018.07.05/_settings { "settings": { "index.routing.allocation.require.box_type": "cold" } } 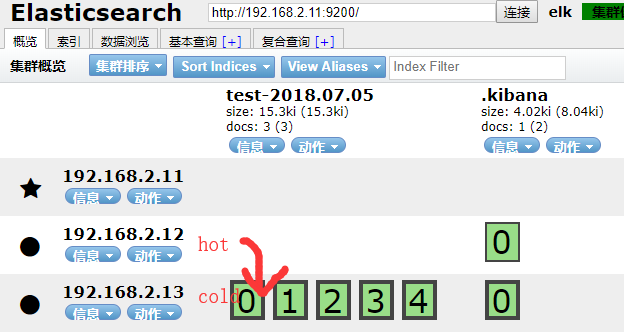
生产中可能每天,或每h,生成一个index.
test-2018.07.01test-2018.07.02test-2018.07.03test-2018.07.04test-2018.07.05...
我可以写一个sh定时任务,每天晚上定时迁移数据.
如我在hot节点只保留7天的数据,7天以前的索引我匹配到, 每天晚上执行以下迁移命令即可.cold节点数据保留1个月?
https://www.cnblogs.com/iiiiher/p/8029062.html
优化点:
1.为了提高吞吐量
path.data:/data1,/data2,/data3,/data4,/data5 可以每个目录挂一块盘
2.如果有10台hot节点,可以设置10个shards
logstash测试
input { stdin { } }output { elasticsearch { index => "test-%{+YYYY.MM.dd}" hosts => ["192.168.2.11:9200"] } stdout {codec => rubydebug}}/usr/local/logstash/bin/logstash -f logstash.yaml --config.reload.automatic 关于es的index template
关于
es数据入库时候都会匹配一个index template,默认匹配的是logstash这个templatetemplate大致分成setting和mappings两部分
- settings主要作用于index的一些相关配置信息,如分片数、副本数,tranlog同步条件、refresh等。
- mappings主要是一些说明信息,大致又分为_all、_source、prpperties这三部分: https://elasticsearch.cn/article/335
根据index name来匹配使用哪个index template. index template属于节点范围,而非全局. 需要给某个节点单独设置index_template(如给设置一些特有的tag).